Submit new samples
Check results
Welcome to FORENSIC
FORest ENteric Source IdentifiCation is a web interface to identify fecal pollution sources using random forest classification and 16S rRNA gene amplicons. It relies on the detection in environmental samples of source-specific fecal bacterial signatures characterized upstream.
How to use FORENSIC
1Samples have to be sequenced by targeting the V4 or V6 hypervariable regions of the 16S rRNA gene using Illumina® platform. We recommend samples with a minimum of 100,000 sequences to be able to detect their fecal signature. Primers used and PCR conditions are described here for V4 (Earth Microbiome V4 primers) and here for V6.
2Reads must be trimmed using CUTADAPT and merged using PEAR according to the V4 or V6 workflow (bash or text version). Warning: some parameters have to be set manually before being used as an automated script. This workflow will generate one fasta file containing your different samples.
3FORENSIC supports only fasta files (not compressed). To date, there is no fasta file size limit, but please consider uploading fasta <5GB. A header line is REQUIRED and consists of the sampleID and the sequence ID separated by a vertical bar "|"
(if you followed the workflow above, you are good to go):>sampleID|sequenceID. A fasta with a wrong header format will cause the server to crash.
Good examples: >BeachSample1|D4ZHLFP1-44-D15PUACXX-2-1101-1236-2324 or >PTRR.145_4|1 O8YZI:01315:00349 orig_bc=GAGTAGAC
Bad examples: >BeachSample1_D4ZHLFP1-44-D15PUACXX-2-1101-1236-2324 or >PTRR.145_4 1 O8YZI:01315:00349 orig_bc=GAGTAGAC
SampleID has to start with a non-numeric character.
Fasta format file examples, representing the Bacteroidales and Clostridiales fecal assemblages in environmental and/or sewage samples (described in Roguet et al. in preparation), is downloadable here for V6 or V4.
Fastq format file examples of the samples described in the fasta are available here for V6 or V4.
A command line (only for mac users) is available here.
Citation
If you use FORENSIC, please consider citing the article below:
Roguet A, Esen ÖC, Eren AM, Newton RJ and McLellan SL (2020). FORENSIC, an online platform for fecal source identification. mSystems, 5(2):e00869-19 [DOI: 10.1128/mSystems.00869-19]
How it works
To identify fecal pollution sources, a classifier was first designed for each source using random forest classification.
A classifier is composed of host-specific and host-preferred sequences that are the most reliable to discriminate between sources. To identify these sequences, the samples of a given source (15-20 samples/source)were compared to the other sources. Classifiers were then trained with the sequences previously selected.
bTo classify an unknown sample, the sequences identical to the ones composing the classifiers are retained, and their relative abundance is calculated.
cAn unknown sample is considered to be contaminated by a source if the majority of these abundances are similar to the relative abundances of the sequences in the classifiers.
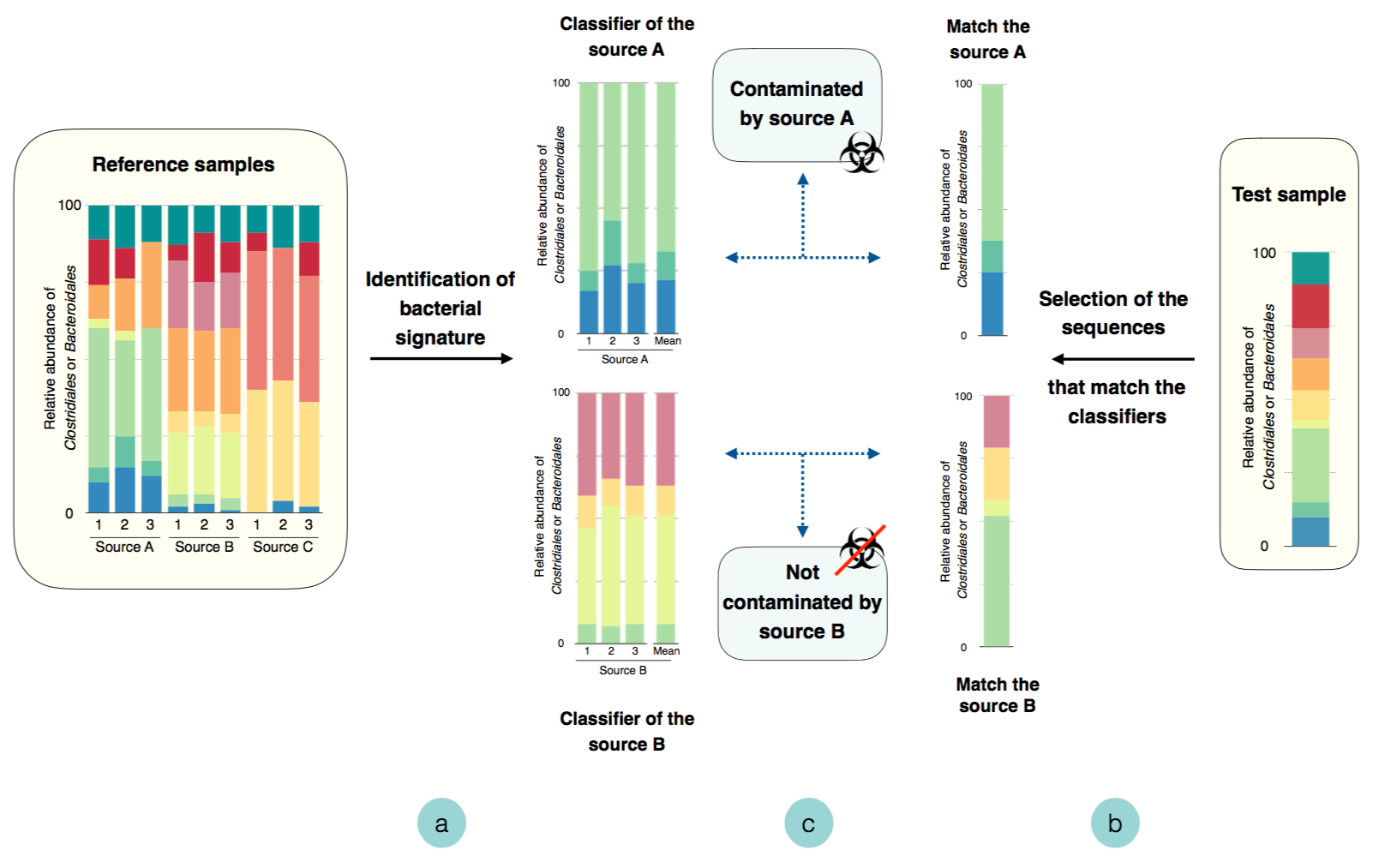
A detailed description of sequences processing, and random forest parameters are available in the paper Roguet A, Eren AM, Newton RJ and McLellan SL (2018). Fecal source identification using random forest. Microbiome, 6:185.
Updates
4-30-20 The legend for "Fecal Source Predictions" results has been simplified: "low confidence (<80% specificity)" has been replaced by "low confidence (trace level detection)" and "low confidence (>80% specificity)" by "low confidence".
It does not affect the interpretation of the results.